CISC352_Quiz1复习笔记
Week1
Search
Search Problems(搜索问题)
组成:
**状态空间(state space):**所有可能出现的“情况/局面”(比如游戏里每一种棋盘摆法、迷宫里每个位置等
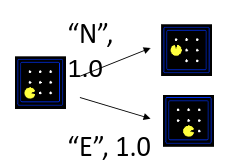
后继函数(successor function)(包含动作与代价):
-
从当前状态出发,你能做哪些动作(actions),做完会到达哪些新状态;
-
每个动作可能还有代价/成本(cost)(图里示例动作 N/E,代价 1.0)。
起始状态 + 目标测试(start state & goal test)
-
从哪里开始(start state)
-
怎么判断“到目标了”(goal test:是否满足目标条件)
State Space 和 Search state
World state(世界状态)
包含环境的所有细节, 例如整张地图里:墙、豆子、怪物、角色位置……每一个细节都算进去。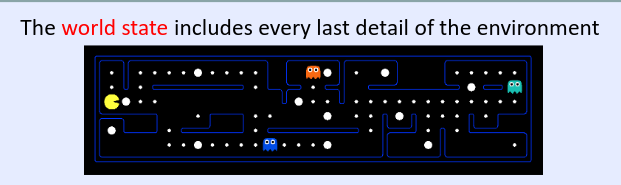
Search state(搜索状态)
只保留“为了规划/解题需要”的信息(抽象 abstraction)
State Space Graph(状态空间图)/Search Trees(搜索树)
State Space Graphs(状态空间图)
用数学方式表示一个搜索问题的图结构
节点(nodes):抽象后的“世界配置/状态”(abstracted world configurations)
边/弧(arcs):从一个状态采取某个动作后到达的后继状态(action results)
目标测试(goal test):对应一组目标节点(可能只有一个)
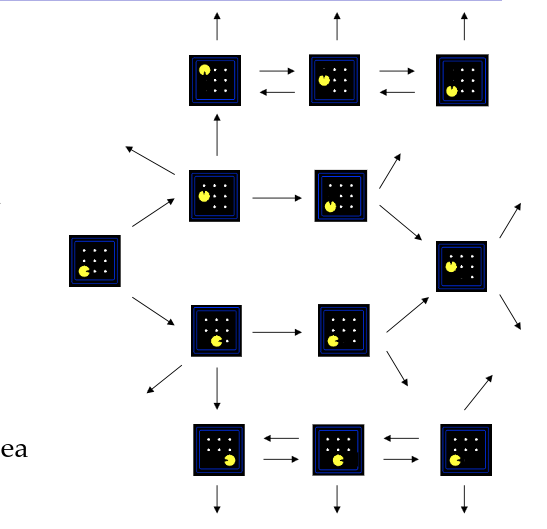
在状态空间图里:每一种状态只出现一次
(不会把同一个状态画成多个不同节点)
Search Tree(搜索树)
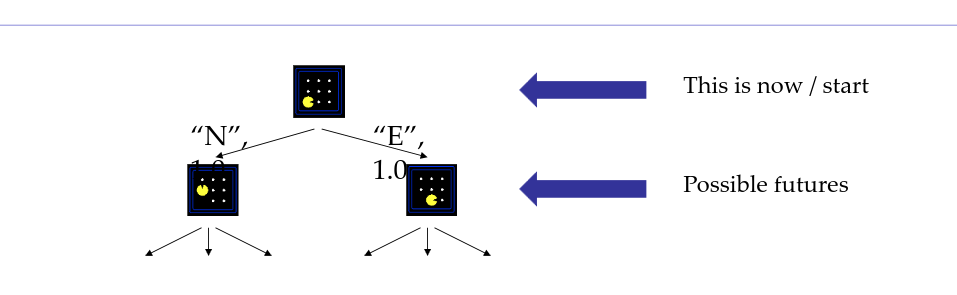
从起点状态出发,把“我接下来可以怎么走”一层层展开形成的树
每条路径 = 一个计划(plan);节点对应“到达某状态的一条具体路径”
同一个状态可能出现多次(因为不同走法到同一状态,在树里会作为不同节点重复出现)
如何搜索?
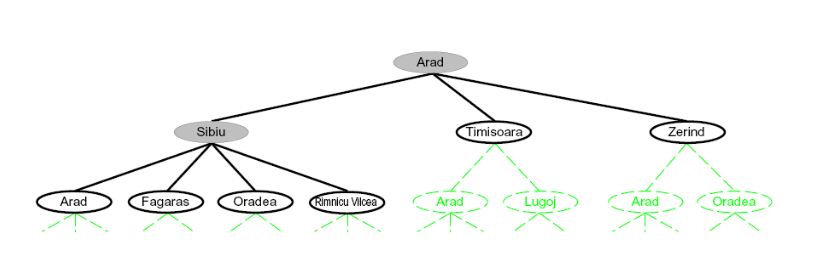
展开可能的计划:把当前节点往外扩展,生成它的子节点(tree nodes),代表“下一步可能去哪/怎么走”。
维护一个 fringe(边缘/前沿):
fringe 指“目前还在考虑、但还没展开的那些部分路径(partial plans)/节点集合”。
简单说:就是待处理队列/列表(之后要从里面挑一个继续展开)。
绿色虚线圈出的节点表示:它们属于当前/后续可能在 fringe 里的候选分支(还没继续深挖的路)。
Week 2: Constraint Satisfaction Problems(CSP)
What is Search For?(搜索是用来干什么的)
对世界的基本假设(Assumptions)
动作是确定性的 (deterministic actions:做了就一定得到那个结果)
状态完全可观测(fully observed state:你知道当前处于什么状态)
状态空间是离散的(discrete state space:状态是一个个可数的)
主要用途
1.Planning(规划):找一串动作
- 目标是找到动作序列把起点带到终点
- 路径本身很重要(the path to the goal is important)
- 不同路径可能有不同的:
- 成本(cost)
- 深度(depth / 步数)
- **启发式(heuristics)**可以提供“更聪明的引导”(根据具体问题提示往哪搜更好)
直观例子:走迷宫 / 导航到目的地——“怎么走”本身就是答案。
2.Identification(识别/满足约束):给变量赋值
- 目标是找到一组变量的赋值(assignments to variables)
- 结果/目标本身更重要,路径怎么找出来不重要
(the goal itself is important, not the path) - 在某些表述下:所有解都在同样深度(all paths at the same depth)
- **CSP(约束满足问题)**是专门用来处理这类识别问题的
直观例子:数独——你关心的是最终填好的格子,不关心你是按什么顺序试出来的。
对比普通搜索问题(Standard search problems)和CSP
普通搜索问题(Standard search problems)
- 状态(state)像“黑箱”:可以是任意数据结构,你不一定知道内部结构怎么组织
- 目标测试(goal test):可以是对状态的任意判断函数
- 后继函数(successor function):也可以是任意规则(怎么从一个状态生成下一个)
CSP
CSP 结构:
- 状态由一组变量组成:X_1, X_2,…
- 每个变量有取值范围(domain):从某个集合 D 里选值(有时每个变量的 domain 还不一样)
- 目标不是“走到哪里”,而是满足一组约束(constraints):
约束规定“哪些变量组合/取值搭配是允许的”(例如 X1 != X_2、某两门课不能同一时间等)
CSP Examples
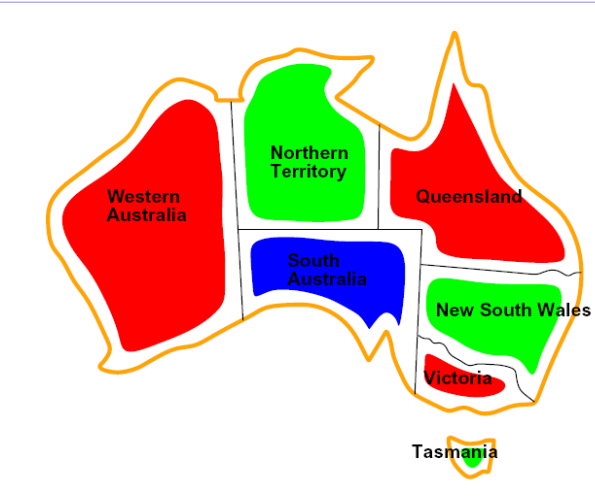
**Variables:**WA,NT,Q,NSW,V,SA,T
Domains: D={red, green, blue}
Constraints: adjacent regions must have
different colors
Implicit: WA≠NT
Explicit: (WA,NT)∈{(red,green),(red,blue),…}
Solutions are assignments satisfying all
constraints, e.g.:
{WA=red, NT=green, Q=red, NSW=green,
V=red, SA=blue, T=green}
Constraint Graphs
Constraint Graphs能够加速搜索
Binary CSP:每条约束最多只涉及 两个变量。
Binary constraint graph:
- 节点(node)= 变量
- 边/弧(edge/arc)= 约束
Varieties of CSPs
离散变量(Discrete Variables)
-
有限域(Finite domains)
-
如果每个变量的域大小是 d,有 n 个变量,那么完整枚举所有赋值大概是 O(d^n)
-
例子:布尔 CSP,包括 布尔可满足性 SAT(经典 NP-complete 问题)。
-
-
无限域(Infinite domains:整数、字符串等)
- 例子:**作业调度(job scheduling)**里,变量可能是每个任务的开始/结束时间(整数时间点)
- 线性约束可解,非线性不可解(Linear constraints solvable, nonlinear undecidable)
线性约束是什么?
满足下面特征的约束就是线性的:
变量只以 一次幂出现:
只允许 常数×变量 的项:
这些项之间做 加/减,再跟常数比较:
或 =, >=
非线性约束是什么?
只要出现以下任意一种情况,就通常是非线性的:
- 变量相乘:xy
- 变量平方/高次幂:x^2, x^3
- 变量在分母:1/x, x/y
- 绝对值、max/min(有时可改写成线性,但原式非线性):|x|, max(x,y)
- 三角函数、指数、对数等:sin x, e^x, log x
总的来说
线性:只有“常数×变量”的加减,比如 3x - 2y + 7
非线性:出现 x^2、xy、1/x、sin x、e^x 等
Varieties of Constraints变量约束
一元约束(Unary constraint)
-
只涉及 1 个变量
-
例子:
SA ≠ green含义:变量 SA 不能取“绿色”,所以从 SA 的候选颜色里把 green 删掉。
二元约束(Binary constraint)
- 涉及 2 个变量
- 例子:
SA ≠ WA
含义:SA 和 WA 不能取同一个值(地图着色里就是相邻不能同色)。
高阶约束(Higher-order constraint)
-
涉及 3 个或更多变量
-
例子:幻算/字母算(cryptarithmetic)的“列约束”
比如在 SEND + MORE = MONEY 里,每一列加法会同时关联多个字母变量和进位变量。
不是“两两关系”,而是一条规则同时管一组变量。
偏好 / 软约束(Preferences / soft constraints)
例如,红色比绿色好。
通常可以用每个变量的成本来表示赋值
Solving CSPs
Standard Search Formulation 标准搜索
-
由当前赋值定义的状态
-
Initial state: the empty assignment, {}
- 空赋值
{}
- 空赋值
-
Successor function: assign a value to an unassigned variable
- 从当前状态怎么扩展到下一个状态?
- 为未赋值变量
-
Goal test: current assignment is complete and satisfies all constraintsc
-
赋值完整:所有变量都已经有值
满足所有约束:例如相邻州不同色等
-
-
Backtracking Search回溯搜索
它是解 CSP 最基础的“非启发式(uninformed)”算法。
-
Idea 1:One variable at a time(一次只处理一个变量)
- 在 CSP 里,一个状态就是“已赋值变量的集合”。
例如{WA=red, NT=green}这个集合:- 先 WA 再 NT 得到它
- 先 NT 再 WA 也得到它
- 在 CSP 里,一个状态就是“已赋值变量的集合”。
-
Idea 2:Check constraints as you go(边走边检查约束)
- 次给一个新变量赋值时,立刻检查它是否和之前已经赋值的变量冲突:
- 如果冲突:这个值肯定不可能扩展成解 → 马上剪枝
- 如果不冲突:才继续往下走
- 次给一个新变量赋值时,立刻检查它是否和之前已经赋值的变量冲突:
Depth first search 结合这两项改进
CSP Search Improvements
Filtering
Forward Checking
Filtering(过滤):
在回溯里,不只是记录“已经赋了什么值”,还要同时记录:
- 每个未赋值变量当前还剩哪些可选值(它的 domain)
- 并且随着赋值推进,持续删掉不可能的值(cross off bad options)
这样可以更早发现无解:如果某个变量的 domain 被删空了 → 立刻回溯。
Forward Checking(前向检查)
当你刚给某个变量 赋值后:
- 只看 与 X 有约束相连的、尚未赋值的邻居变量 Y
- 从 Y 的 domain 中删掉那些 会与 X 的当前赋值冲突 的值
Constraint Propagation
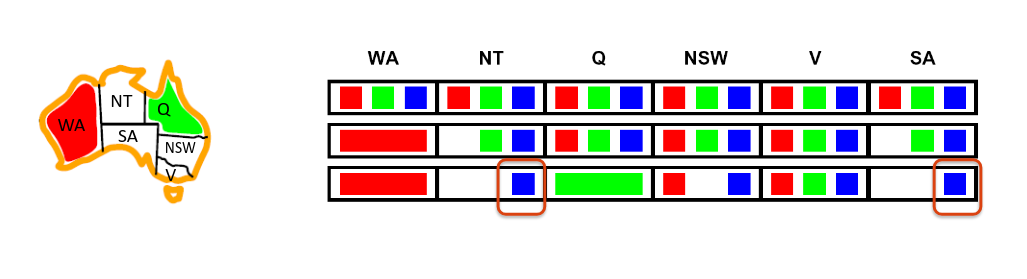
Forward checking 只会把信息从 “已赋值变量 → 未赋值邻居变量” 传播:
- 你给某个变量定了颜色
- 就从它相邻的未赋值变量的 domain 里删掉冲突颜色
但它不会主动去推理“两个未赋值变量之间的矛盾”,所以有些“注定失败”不会被提前发现。
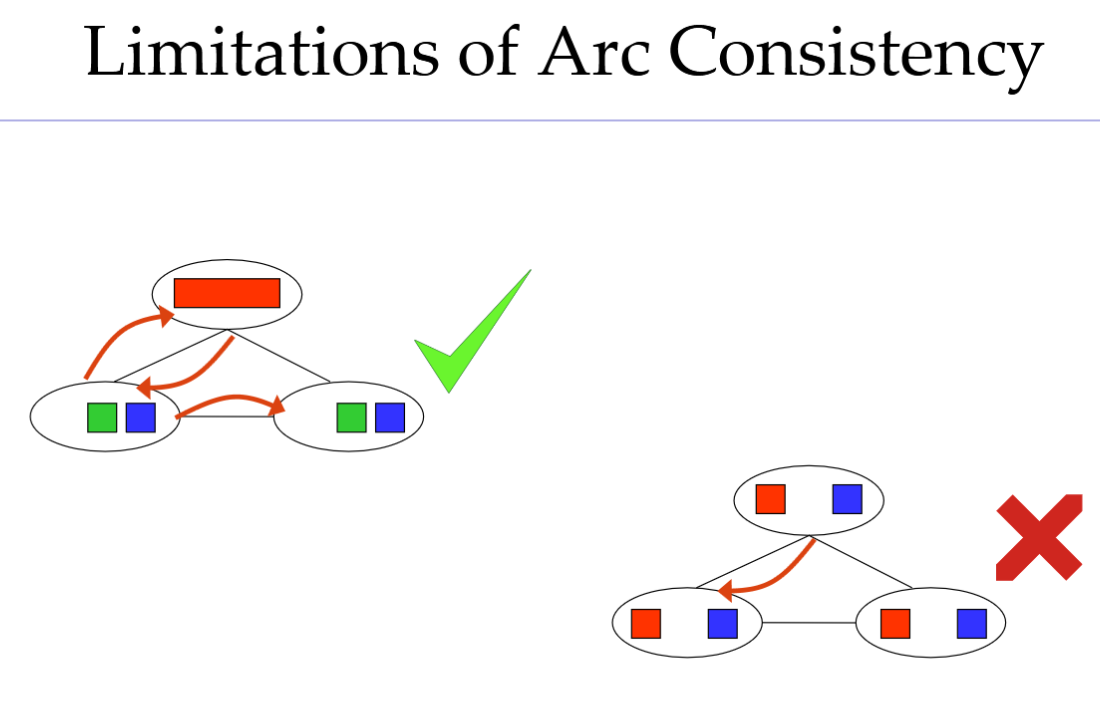
Arc consistency弧一致性
一种简单的传播形式可确保所有弧一致性
• 弧一致性检测能比前向检查更早发现错误
• 可作为预处理器运行,或在每次赋值后执行
重要:若X丢失Value,需重新检查X的邻居!( Delete
from the tail!)
局限性
做完弧一致性之后可能出现的三种情况
情况 A:可能只剩一个解
情况 B:可能还剩多个解
情况 C:可能根本没解,但 AC 看不出来
K-Consistency K-一致性
1-Consistency(unary constraints)
- 只看一元约束
2-Consistency(binary constraints)
- 只看二元约束
K-Consistency
-
对于每个k个节点,任何对k-1个节点的分配均可扩展至第k个节点
-
对任何三个变量 X,Y,Z,只要你给其中两个 X,Y 赋值且不冲突,就总能给第三个 Z 找到一个值,让三者一起不冲突。
Strong K-Consistency
强 k-一致性 = 同时满足:
- 1-一致性(节点一致性)
- 2-一致性(弧一致性)
- 3-一致性
- …
- k-一致性
结论:强 n-一致性 ⇒ 可以不回溯求解
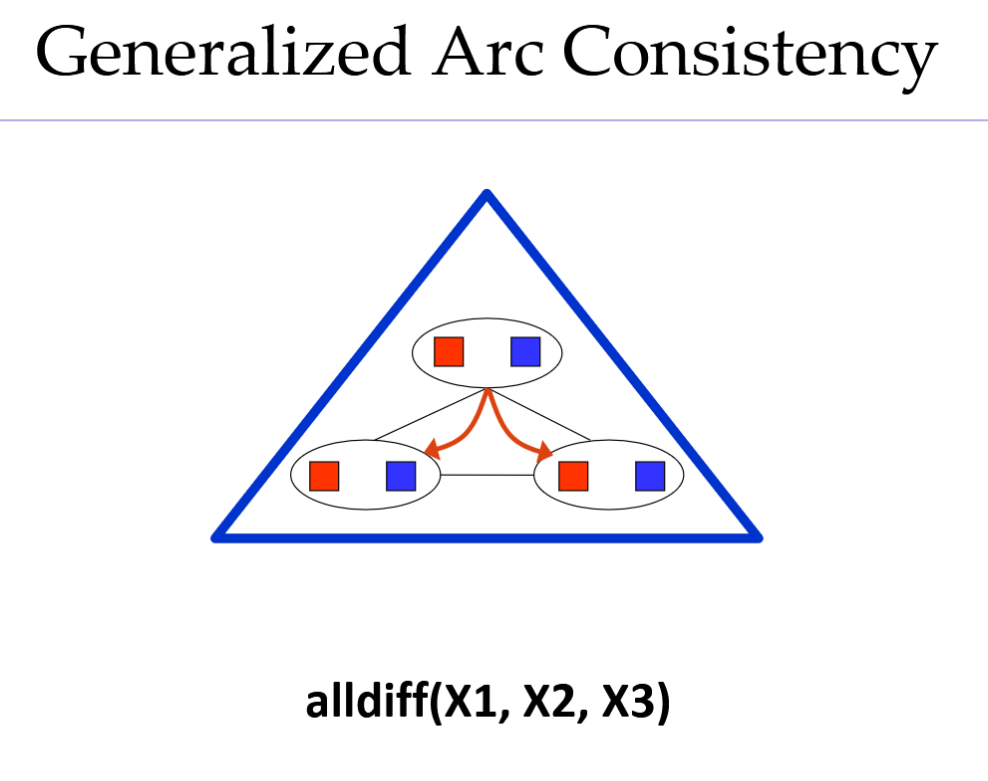
Generalized Arc Consistency
对节点的任何分配都可以扩展为
在共享约束的变量中的分配
Depth-First Search
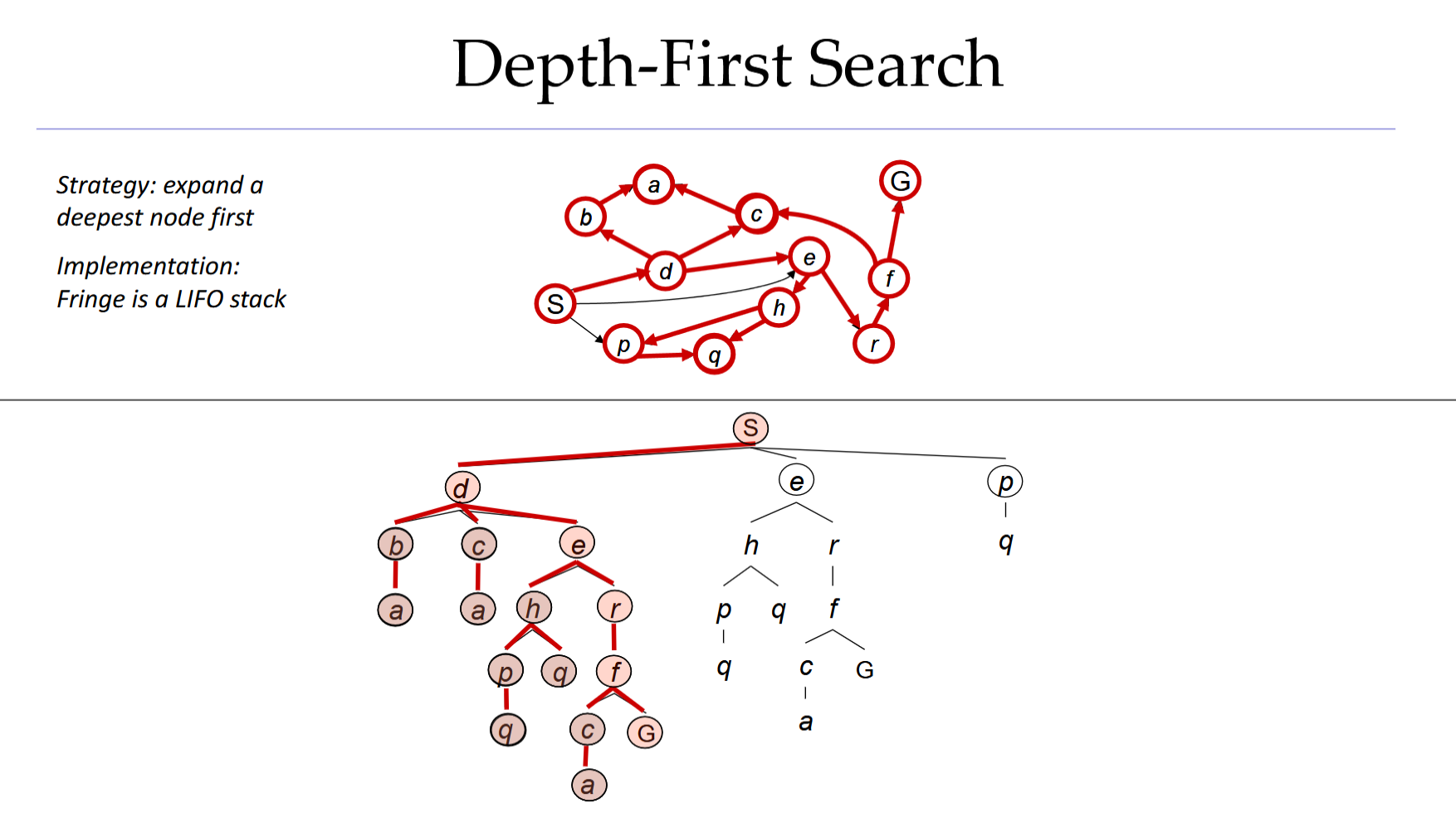
S->D->b->a->c->a->e->h->p->q->q->r->f->c->a->g
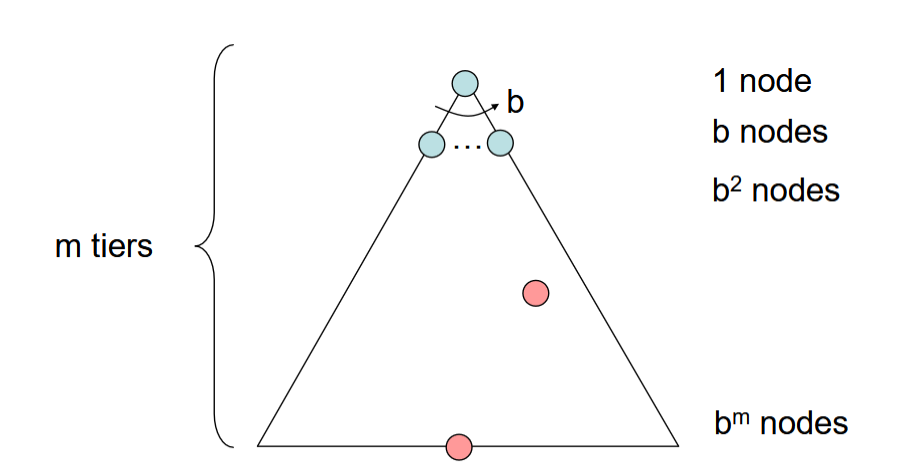
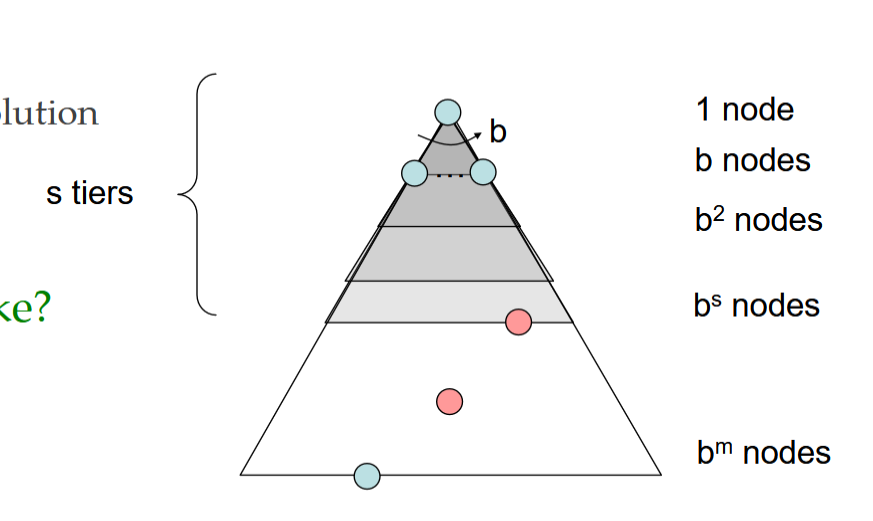
Complexity:
- b is the branching factor
- m is the maximum depth
- solutions at various depths
1 + b + b2 + … bm = O()
complete?
- m could be infinite, so only if we prevent cycles 由于m是无限的所以需要避免循环
optimal?
- No, it finds the “leftmost” solution, regardless of depth or cost
Breadth-First Search
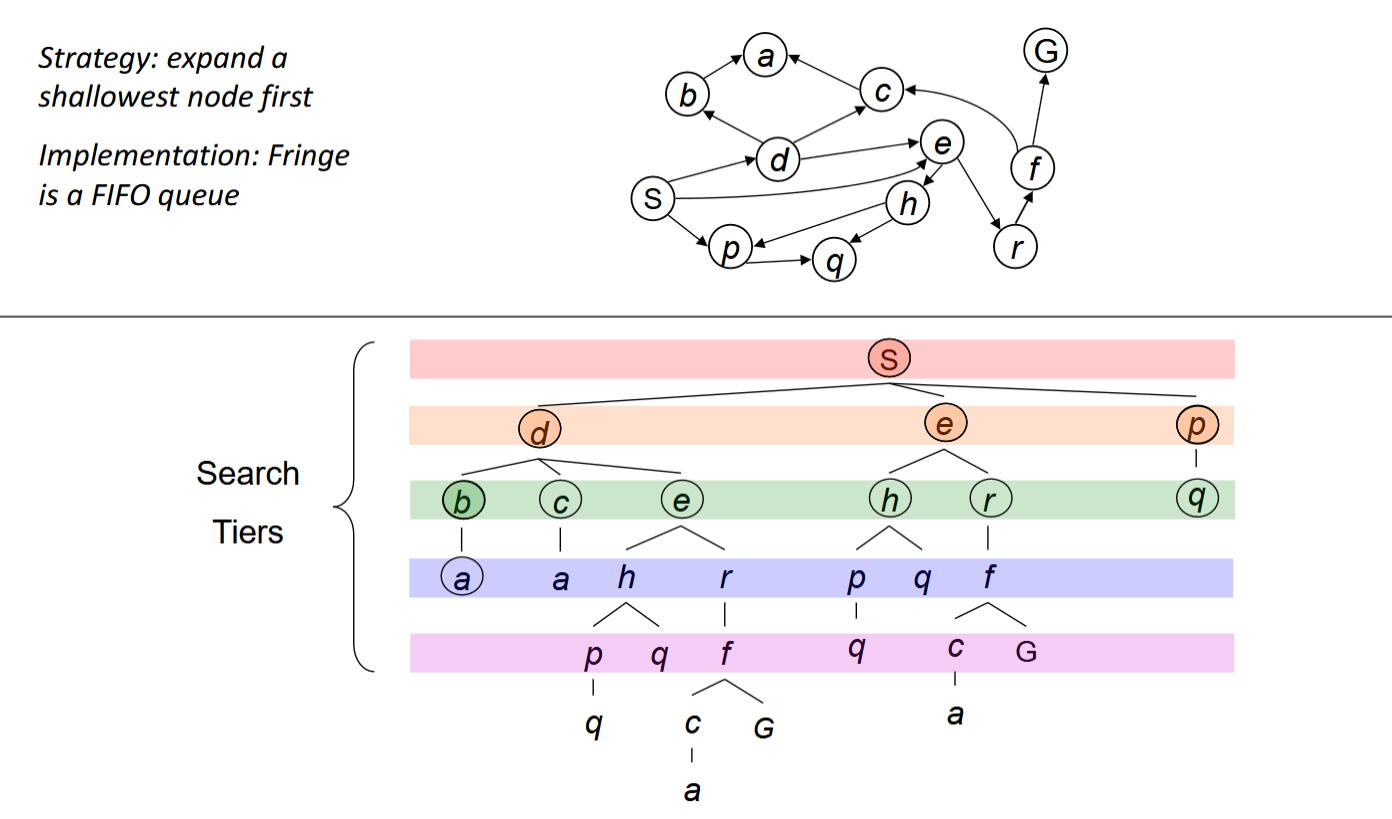
S->d->e->p->b->c->e->h->r->q…
Complexity:O()
complete?
- s must be finite if a solution exists
optimal?
- Only if costs are all 1 (more on costs later)
Iterative Deepening
A->b->c
A->B->D->E->c->f->g
Cost-Based Search
Uniform Cost Search(Dijkstra’s algorithm)
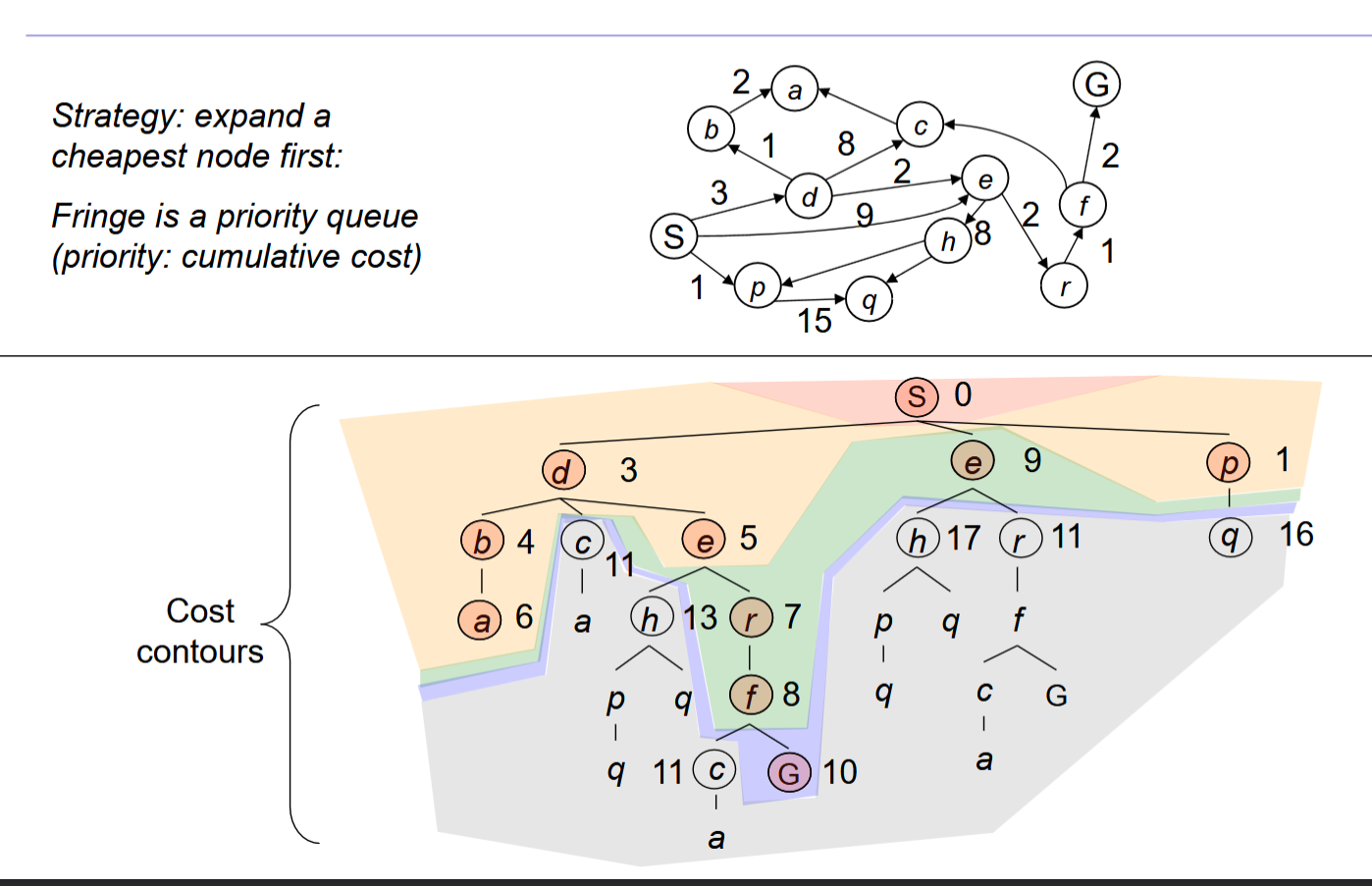
S->p->d->e->b->a->r-f->e->G
Fringe 的变化(优先队列内容):
Fringe: [ S(0) ]->[ p(1), d(3), e(9) ]-> [ d(3), e(9), q(16) ]
将S到达每个节点的总Cost作为树的cost,然后通过优先队列从走过节点的临近节点中找cost最低的走
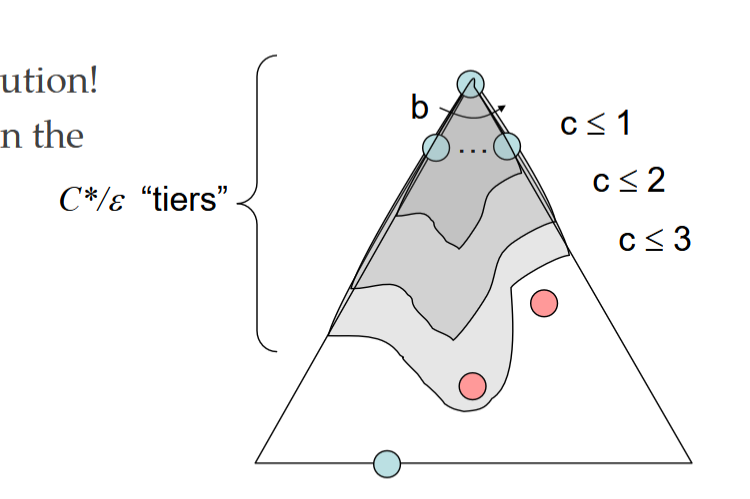
compexity
-
If that solution costs C* and arcs cost at least ε , then the “effective depth” is roughly C*/ε
-
Takes time O() (exponential in effective depth)
complete?
- Yes
optimal?
- Yes! (Proof next lecture via A*)
The One Queue
- 所有这些搜索算法除了边界(fringe)策略外都相同
- 从概念上讲,所有边界都是优先队列(即带有优先级的节点集合)
- 实际上,对于深度优先搜索(DFS)和广度优先搜索(BFS),可以通过使用栈和队列来避免实际优先队列的 log(n) 开销
- 甚至可以编写一个实现,接受一个可变的排队对象
Week 3
Heuristics & Greedy Search
Search Heuristics
heuristic是:
▪ 一个估计某个状态离目标有多近的函数
▪ 为特定搜索问题设计
▪ 路径寻路
▪ 示例:用于寻路的 Manhattan distance(垂直)、 Euclidea distnce(斜线)
Greedy Search
展开看起来最接近的节点
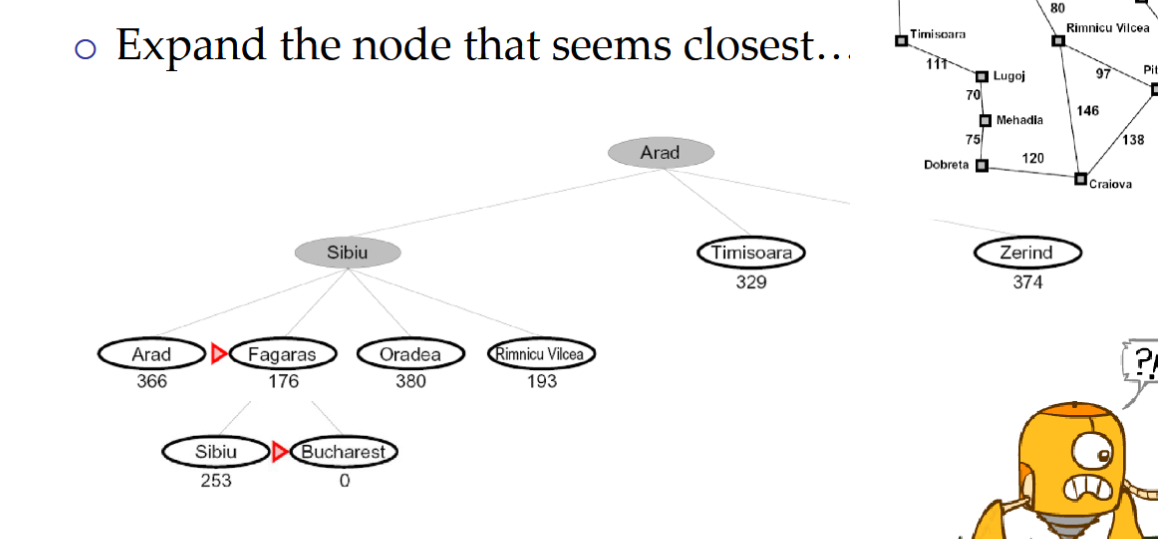
Is it optimal?
No. Resulting path to Bucharest is not the shortest!
策略(Strategy):扩展认为最接近目标状态的节点
- Heuristic::估计每个状态到最近目标的距离
常见情况:
-
最优优先会直接带你走向(错误的)目标
-
最坏情况:如同被错误引导的深度优先搜索
A* Search
结合UCS和Greedy算法
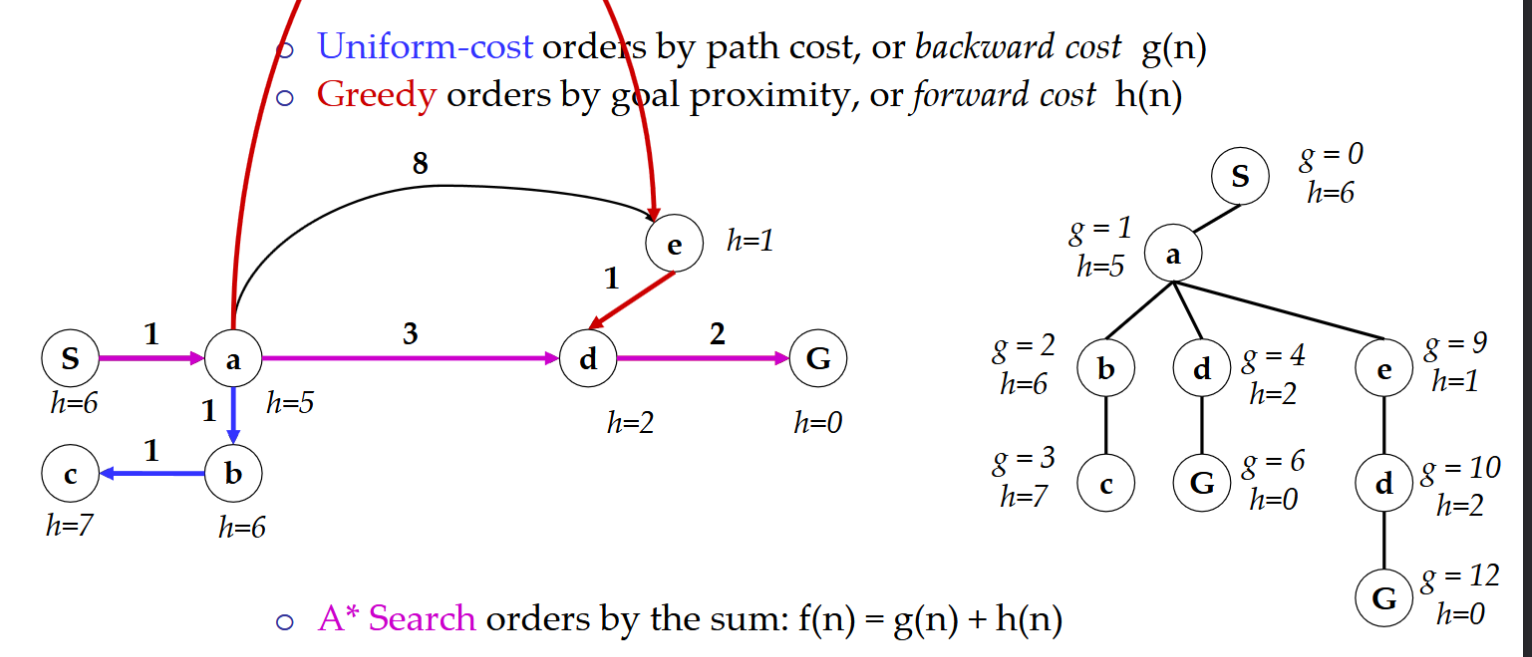
使用 g(n)+h(n)的结果来估算距离
A*算法何时应终止?
当目标节点从优先节点dequeue时
每次入queue后会进行排序
Admissibility
heuristic 当满足以下条件则是admissible (optimistic)的:
是到最近目标的实际cost
Optimality of A* Tree Search
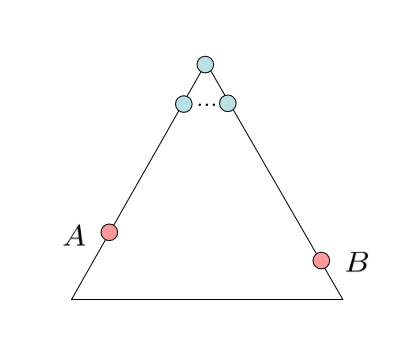
假设:
- A 是一个最优(optimal)目标节点
- B 是一个次优(suboptimal)目标节点
- h 是admissible
结论:A 将在 边缘 之前 被弹出
- 1.f(n) is less or equal to f(A)
- 2.f(A) is less than f(B)
- 3.n expands before B
所有出发的Ansestor,A在B之前扩展
- A在B之前扩展
- A*搜索是最优的
A* 的性质
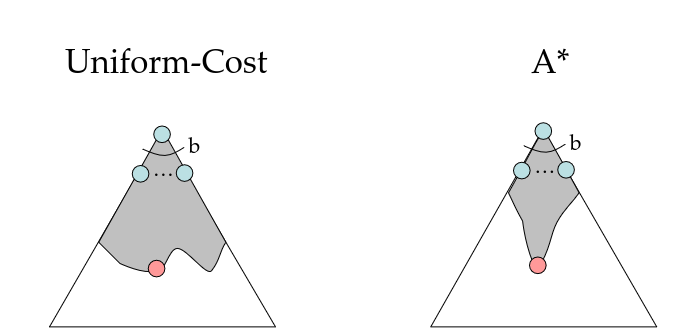
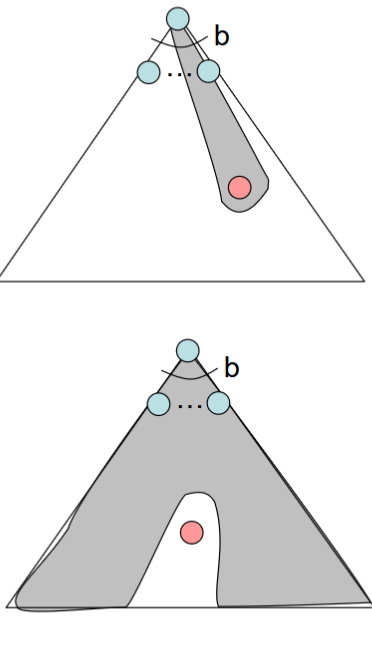
UCS vs A* Contours
Uniform-cost在所有“方向”上同等地扩展
A* 主要朝目标扩展,但也会分散(hedge)策略以确保最优性